
你有没有看过那种数字人一体机视频,声音明明很流畅,但嘴巴动作总感觉慢半拍,或者突然抽搐一下?这通常不是网络延迟,而是语音驱动口型的算法被“脏数据”干扰了。而总谐波失真0.1%,就是那个拒绝破音和延迟的关键。

语音驱动口型的原理,简单说就是把声音波形实时转换成一系列嘴部动作参数。如果麦克风产生的波形失真大,波形上就会出现不该有的毛刺或额外谐波。算法看到这些毛刺,会误以为是新的发音动作,于是频繁调整口型,导致抖动或延迟。而只有用了失真只有0.1%麦克风的数字人一体机,输出的波形平滑、干净,算法一眼就能看出哪里是元音、哪里是辅音,口型变化自然流畅。
下面通过表格对比高失真麦克风与爱镭仕0.1%低失真麦克风数字人在关键指标上的差异:
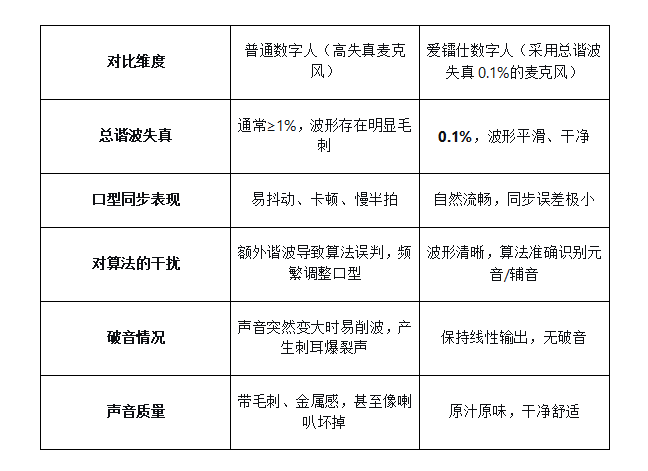
经第三方实测,爱镭仕采用总谐波失真0.1%麦克风的数字人,比市面上普通的数字人口型同步更精准、声音更干净。
举个例子:你说“苹果”这个词。低失真麦克风输出的波形是两个清晰的声音包络,算法驱动嘴巴先张大再合拢,完美匹配。高失真麦克风输出的波形可能在“苹”和“果”之间多出一个奇怪的尖峰,算法以为你发了第三个音,嘴巴莫名其妙地动了一下,看起来就像口吃或者卡顿。
所以,想让你的数字人说话时口型自然、声音干净,请认准总谐波失真0.1%。的数字人互动设备,而爱镭仕的数字人所采用的麦克风总谐波失真就是在0.1%以内,所以我们的数字人拾音特别精准。


